Differences between machine learning and software engineering
Software engineering is the art of automating a task by writing rules for a computer to follow. Machine learning goes a step further: it automates the task of writing the rules. How do traditional software engineering and machine learning differ? Are there any similarities?
Developer perspective
The starting points for traditional software engineering and machine learning are quite similar. Both aim to solve problems and both start by getting familiar with the problem domain: discussing with people, exploring existing software and databases. The differences are in the execution.
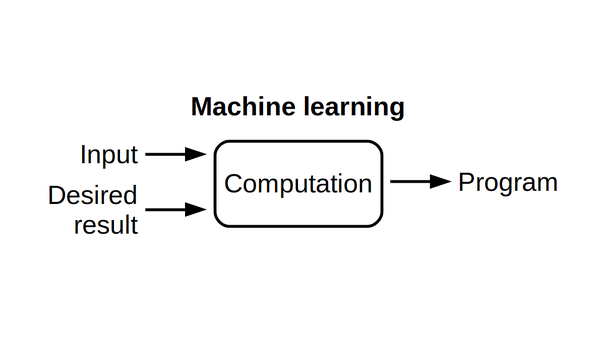
Software engineers use their human ingenuity to come up with a solution and formulate it as a precise program a computer can execute. Data scientists, that is, people who implements machine learning systems, don't try to write down a program by themselves. Instead, they collect input data (dashboard video and other sensor feeds of a car, for example) and desired target values (the throttle level and the angle of the steering wheel). Next, they instruct a computer to find a program that computes an output for each input value (a program that drives a car given the sensor inputs).
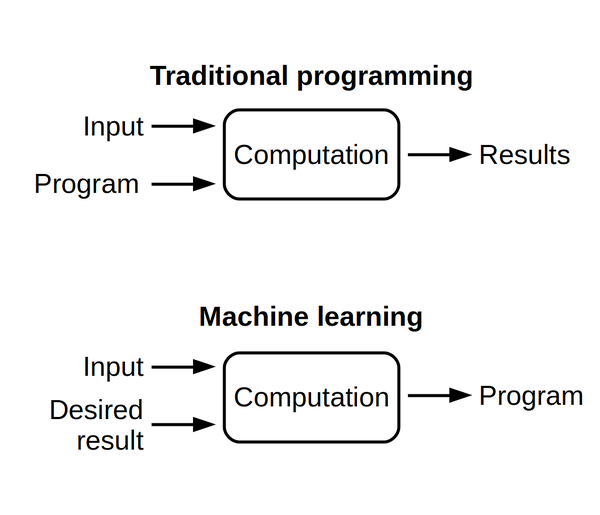
Traditionally programmers automate tasks by writing programs. In machine learning, a computer finds a program that fits to data.
A software engineer is concerned with the correctness in every corner case. Meanwhile, a data scientist has to be much more comfortable with uncertainty and variability. After all, machine learning is all about mining statistical patterns from data. Because of the inherently statistical nature of machine learning, it is more flexible on complex problems, but also more difficult to interpret and debug.
Developing a machine learning application is even more iterative and explorative process than software engineering. Machine learning is applied on problems that are too complicated for humans to figure out (that is why we ask a computer to find a solution for us!). Therefore, a data scientist has to embrace experimental attitude and be prepared to test a few approaches before settling on a satisfying one.
From the outside, the modes of work looks very similar: both species of professionals spend a lot of time hunched over a laptop. Data scientists spend a lot of their time writing code in Python or other general-purpose programming language just like traditional programmers. The majority of time in a machine learning project is consumed by tasks that are best carried out by traditional programming: writing scripts for merging, cleaning up and visualizing data, and integrating the machine learning subsystem with the rest of the application. Certainly the toolkits do have their differences, too. Data scientists are familiar with linear regression and other statistical algorithms while traditional programmers known REST APIs and web frameworks inside out.
Product perspective
When does a product benefit from machine learning? Will there be any use for traditional software engineering in the future or will machine learning consume all of software development?
No, machine learning will not displace traditional software engineering. Most types of problems that are solved with software engineering today, will be carried out by traditional programming also in the future. Machine learning, on the other hand, provides a way to tackle new kinds of problems, the kinds that have been unfeasible to solve previously. Tasks that humans perform with relative ease but that can't be formulated as exact rules (detecting objects in images, driving a car, etc.) are prime candidates for machine learning solutions. Machine learning might be the correct solution also if a software has to adapt to regular changes in its environment.
There are some limitations, however. Learning rules from data requires that you have a large data set of typical cases available. Furthermore, the data must be tagged with the desired outcome. Sometimes suitable data is being generated as a side effect of some existing business process or is published as open data. If not, collecting and labeling data can require considerable effort which might be expensive.
It's really a continuum
In this article, I have contrasted machine learning and traditional programming to better highlight their characteristics. This may make the distinction appear starker than it really is. It is rather a continuum of how much the application functionality is affected by data in contrast to explicit decisions by a programmer.
Let's imagine building a search engine for Wikipedia. In the rigid programming extreme, a search engine might simply return all documents which contain the search terms exactly. Not all terms are equally descriptive, however. Terms that occur frequently in a cluster of documents, but are quite rare overall, are distinctive and should have greater influence on the ranking of the documents. In this case the functionality of the search engine depends partly on the data, namely the term frequencies. Another step towards better utilization of data would be the PageRank algorithm which identifies important pages by analyzing the network of links between the pages. Google resides even further on the machine learning end of the spectrum. It uses a mix of signals to try to capture the semantic content of the search terms and aims to provides meaningful answers, not just matching search terms.
There is also another way how machine learning and traditional programming will approach each other. I believe that in the future it gets easier to experiment with intelligent features, such as recommendations or machine translation. More and more machine learning solutions will be published as handy services and reusable components.
Machine learning complements traditional programming by mining rules from data. It is useful in complicated cases where writing the rules by hand is unfeasible. Traditional programming and machine learning have their distinctions but also share a close kinship.
- Summarizing questions
- What are the similarities between software engineering and machine learning?
- Traditional software engineering and machine learning are quite similar. Both aim to solve problems and both start by getting familiar with the problem domain by discussing with people, exploring existing software and databases.
- What are the methodology differences between software engineering and machine learning?
- Software engineers use human ingenuity to come up with a solution and formulate it as a precise program a computer can execute. Data scientists, that is, people who implements machine learning systems, don't try to write down a program by themselves. Instead, they collect input data, desired target values and instruct a computer to find a program that computes an output for each input value.
- Will machine learning replace software engineering?
- No. Machine learning complements traditional programming by mining rules from data. Machine learning is specifically useful in complicated cases where writing the rules by hand is unfeasible.
 Antti AjankiLead Data Scientist
Antti AjankiLead Data Scientist