Tech Pick of the Week: Rx for .NET and RxJava for Android
There are plenty of resources about how Rx (Reactive Extensions) can be used to make handling of streams of data much easier, but very little has been said about how one should go about building whole applications around Rx. How should Rx be incorporated into mobile applications (with RxJava for Android or Rx.NET in mind)?

I learned from my first dive into Rx that one should not go all-in immediately. It has fundamental changes on how data should be stored, fetched, and modified, especially if you are used to creating traditional event-driven application architectures which assume that model and controller code run on the UI-thread, with additional worker threads doing intensive processing and I/O. When applying Rx to your apps, I would start off by using it at the extremities first while keeping your precious model code traditionally imperative until you are more comfortable with the fundamentals.
Rx for external data sources
If, like most apps, you need to make HTTP requests to fetch data, this would be a good starting point for switching to Rx’s Observables. It removes the need to deal with threading and synchronization while still providing fully asynchronous behavior. It is very simple to wrap an Android HttpURLConnection in an Observable when using RxJava for Android.
If, however, you are developing for Windows Phone 8 or Windows 8, using TPL (Task Parallel Library) may be the preferred approach, especially since the platform APIs have been designed to provide asynchronous goodness with pretty much just an “await” keyword. In this case, think about what you are trying to achieve. Is the result of your operation an enumerable? If so, then use Rx to represent it as a stream of data. If your result is just a singular return value or void, then perhaps TPL provides all you need (see discussion here). But I would go a step further here and say just wrap your Task in an Observable. Your interfaces will remain consistent and your calling code can declaratively handle the results of the task using Rx functions. The same argument applies for replacing AsyncTasks in Android with Observables.
Rx at the view level
Once you have dipped your foot in with external sources of data, you can start replacing imperative with declarative code at the other extreme, the view and the controllers. Bart De Smet gives a very nice example in one of his talks about Rx. He uses a textbox to trigger searches for word suggestions from the web using the contents of the textbox as the search query. This is a very common functionality in mobile apps. The code to handle changes in the textbox goes like this in C# (slightly modified):
IObservable input = Observable.FromEventPattern(textbox, "TextChanged")
.Select(_ => textbox.Text)
.Throttle(TimeSpan.FromSeconds(0.5))
.DistinctUntilChanged();What do we achieve with this? We transform a TextChanged event using FromEventPattern() to grab the current contents of the textbox with Select() every time the user inputs a character. Then we Throttle() that stream of data to emit the contents of the textbox at most every half a second to avoid flooding the server with unnecessary requests. Finally, we call DistinctUntilChanged() which makes sure we never send the same string of characters twice in a row (another unnecessary request). We can deduce the intent much easier from this declarative code than we could from its imperative counterpart, where we would be forced to use callbacks, timers, cancellation, and string comparisons shotgun sprayed all over our code file. The Java example would differ a bit, as we would need replace the FromEventPattern() call with a custom observable which wraps a textbox listener.
Rx at the model level
With the extremities Rx-ified, let’s see what we can accomplish by making our models a bit more reactive. Consider the diagram below. There is a view that contains a list, and this list reflects a collection of data items in your model. Normally you would fetch the current list of data when constructing the view, then listen to changes in that model, such as the addition of a data item.

What would happen if you convert getData() call to return an Observable instead? It would eliminate the need to conceptually separate the handling of the initial state and later modifications at the point of the Observer. You can consider the list of data as an infinite stream that you subscribe to, which sends the original list of items one by one and any later additional updates to any observer that subscribes to it. With RxJava, you could accomplish this at the view level with a simple (I’m cheating a bit and using lambda notation for brevity).
Subscription subscription = model.getData()
.subscribe((item) => addItemToList(item));As soon as your model provides Observables, you can bring the whole power of Rx to play. Let’s say the items are emails in an inbox, and we want the list to display only the first 5 emails that have arrived from me@example.com. All this can be defined declaratively:
Subscription subscription = model.getData()
.where((item) => item.getSender().equals(“me@example.com”))
.take(5)
.subscribe((item) => addItemToList(item));Now take the case where we are using the repository pattern to abstract away the source of our data as shown in the diagram below.
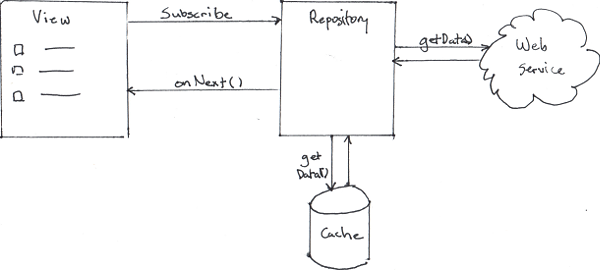
There is web service that provides an interface to get data items, and we have combined it with a cache that also stores some of those data items. If both data sources are implemented as Observables, we can simply define our repository to return a concatenation of both streams as follows
public class Repository {
...
public Observable<data> getData() {
return Observable.concat(mCache.getData(), mWebService.getData());
}
}That code will first return the results from the cache, followed by results from the web service as a single stream of data. We can leave the code in our view as it was above, and it will function as expected.
A word of warning
I would encourage caution when starting to use Rx in model code, especially if you use Rx schedulers other than the UI thread. Before you go down this path, familiarize yourself more with functional programming principles. Depending on your needs, you may need to avoid side-effects as much as possible. When you ultimately do create side-effects you might need to protect yourself from race-conditions and ensure thread-safety with code of your own, and that is a high-risk proposition.
Additional reading
 Olli SalonenSenior Technical Lead
Olli SalonenSenior Technical Lead

