Nyckelkomponenter för att bygga skräddarsydda generativa AI-lösningar
När du börjar utforska den affärsmässiga potentialen i AI, är startpunkten ofta off-the-shelf lösningar. Men förr eller senare stöter du på deras begränsningar. Och när alla andra också använder samma verktyg, blir det svårt att behålla en konkurrensfördel. Förr eller senare kommer därför behovet av att utveckla AI-lösningar som är anpassade till just din data, dina processer, behov och arbetssätt.

Det finns många sätt att bygga skräddarsydda AI-lösningar. Skräddarsytt betyder sällan att bygga allt från grunden,snarare handlar det om att kombinera de senaste modellerna, AI- och ML-tjänsterna, biblioteken och verktygen till en lösning som passar just dig.
Att ta fram lösningar på demo-nivå är idag relativt enkelt med låg- eller helt kodfria verktyg. Men att bygga robusta lösningar för produktion, som verkligen skapar värde, kräver fortfarande mycket arbete. Det finns ingen universallösning. Tillvägagångssättet beror helt på vilken data, vilka promptar och vilka mål som gäller i varje enskilt fall.
Här nedan har vi samlat de viktigaste komponenterna du behöver ta hänsyn till.
Stora språkmodeller (LLM), stora multimodala modeller (LMM) och små språkmodeller (SLM)
Utvecklingen av generativ AI börjar med en modell. Under 2023 innebar det i praktiken nästan alltid att använda GPT-3.5 eller GPT-4. Men idag är landskapet betydligt mer konkurrensutsatt, med en växande uppsättning högpresterande proprietära modeller som GPT-4o och o1, Claude 3.5 Sonnet och Gemini 1.5. Många av dem är dessutom multimodala – de kan alltså hantera ljud-, bild- eller videodata, utöver text.
De stora proprietära modellerna får nu sällskap av starka open source-alternativ, som Llama-3, och extremt kostnadseffektiva små språkmodeller som Phi-3. Det börjar bli riktigt trångt på marknaden.
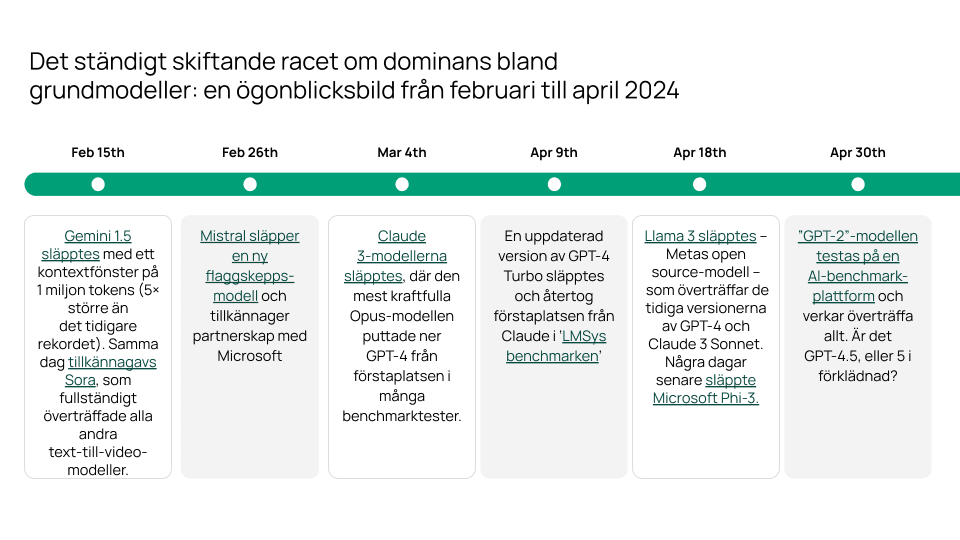
Som du kan se i tidslinjen ovan rör det på sig,snabbt. Bara en månad efter att vi skapade den här översikten släpptes GPT-4o. Sedan följde Claude 3.5 Sonnet, Llama 3 405B, Mistral Large 2, Grok 2, GPT-4o mini, o1 och mycket mer. Det är helt enkelt upp till dig att följa utvecklingskarusellen vidare med hjälp av benchmark-verktyg som artificial analysis eller Livebench.
Den här konkurrensen är en fördel för oss användare,LLM:er har blivit ungefär 1000 gånger billigare och 10 gånger bättre på bara två år. Modellerna specialiserar sig alltmer, så räkna med att kombinera flera i en och samma lösning.
API-leverantörer för åtkomst till AI-modeller
För att komma åt proprietära modeller i utvecklingssyfte behöver du använda ett API. Azure är i dagsläget den ledande leverantören, med exklusiv tillgång till OpenAIs modeller, ett brett utbud av kompletterande AI- och ML-tjänster, starka utvecklarverktyg, det mest generösa finansieringsprogrammet, flera EU-baserade driftsalternativ och robust dataskydd.
Men andra stora molnleverantörer satsar tungt för att komma ikapp. Google och AWS har båda investerat miljarder i Anthropic, en av OpenAIs främsta konkurrenter. Avståndet till Azure minskar, och både AWS Bedrock och Googles Vertex AI är redan fullgoda alternativ i de flesta sammanhang.

En växande skara AI-native aktörer etablerar sig också på infrastrukturmarknaden, stödda av miljarder i riskkapital. Groq, Fireworks.ai och Together.ai erbjuder till exempel innovationer som möjliggör betydligt snabbare inferens (d.v.s. modellernas svarstid) och enkel självhosting av open source-modeller. Groq är väl värt att testa, det är riktigt imponerande.
De här nya aktörerna är kanske inte helt redo för storskalig företagsanvändning ännu, men innovationstakten är minst sagt spännande. Precis som med modellerna bör du vara inställd på att använda flera olika API-leverantörer.
Prompt engineering
När du har satt upp din utvecklingsmiljö bör utgångspunkten alltid vara prompt engineering, alltså att instruera modellen hur den ska agera utifrån din prompt.
Det är det enklaste sättet att påverka en LLM:s output, och det gör att du kan börja testa, lära och iterera på bara några sekunder. Det är imponerande hur mycket du redan kan åstadkomma med en LLM:s grundfunktioner – helt utan kod.
Prompt engineering handlar också om mycket mer än vad du kanske är van vid från samtal med ChatGPT. Den här guiden visar olika tekniker för att hantera mer komplexa fall och få ut ännu bättre resultat. TL;DR – några saker är särskilt viktiga:
- Att be LLM:er planera, resonera och iterera kan ha stor påverkan på kvaliteten i deras svar
- För komplexa uppgifter bör du inte försöka skriva en enda komplicerad prompt, bryt i stället ner uppgiften i en kedja av enklare prompts
Retrieval Augmented Generation (RAG), vektordatabaser och hybridsökning
RAG handlar om att ge LLM:er tillgång till information som ligger utanför deras träningsdata. Det är det självklara sättet att kombinera en LLM:s språk- och resonemangsförmåga med din egen kunskap och dina data.
I praktiken innebär det att du omvandlar textdata till så kallade vektorembeddings med hjälp av en embeddingsmodell (se benchmarks), och lagrar dem i en vektordatabas som Pinecone, Azure AI Search eller pgvector (fler benchmarks). När en användare ställer en fråga till LLM:en, omvandlas den till en sökfråga i databasen. De mest relevanta träffarna skickas sedan tillbaka till modellen tillsammans med frågan, med instruktionen att enbart svara utifrån det givna sammanhanget.
I stort sett alla våra generativa AI-case har innehållit någon form av RAG. Att skapa något som levererar verkligt värde i produktion kräver betydligt mer än att lägga ett chattgränssnitt ovanpå en sökfunktion. En LLM:s svar blir aldrig bättre än det sammanhang den får att utgå från. Om dina sökresultat i till exempel SharePoint eller Google Drive är bristfälliga (vilket de ofta är) kommer du bara få mer välsvarvade – men fortfarande irrelevanta – svar.
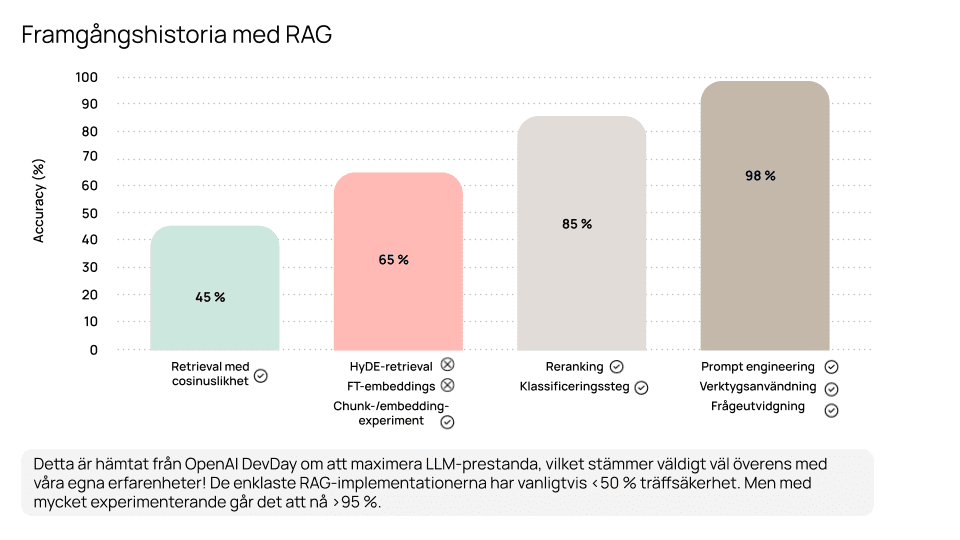
Därför har vi lärt oss att hantera en omfattande verktygslåda för att förbättra kontextens kvalitet: exakt textextraktion, olika chunking-metoder, metadataextraktion, klassificering, sökrelevansjustering, reranking, avsiktsigenkänning, frågeutvidgning, prompt engineering – och mycket mer.
Att använda kunskapsgrafer för högkvalitativ RAG
Kunskapsgrafer är ett framväxande sätt att skapa RAG-lösningar med högre precision och kvalitet. Med grafdatabaser som Neo4J kan du representera relationer mellan olika informationsdelar, och kombinera både text- och numerisk data.
I stället för att mata LLM:en med enstaka informationsbitar kan du ge ett rikare sammanhang genom att visa flera sammankopplade delar i grafstruktur. Det här blir särskilt kraftfullt när relationerna mellan datapunkter bär på avgörande information – till exempel i juridiska dokument som hänvisar till olika paragrafer och lagar, eller i rekommendationssystem där vi använder beteenden från liknande användare för att föreslå innehåll eller åtgärder.
Grafdatabaser har funnits länge, men har hittills haft svårt att slå igenom brett. Med LLM:er kan det bli enklare – de kan hjälpa till att bygga grafer direkt från ostrukturerad rådata och automatisera delar av relationskartläggningen. Dessutom kan de tolka naturligt språk och omvandla det till graffrågor i databasen.
Det här området är fortfarande relativt outforskat, med få experter och begränsat med resurser att lära från. Så när relationer mellan datapunkter är viktiga kan det vara klokt att börja med att kombinera relations- och vektordatabaser innan du går direkt på grafer.
Finjustering av generativa AI-modeller för specifika uppgifter
Finjustering innebär att du tränar en grundmodell på en uppgiftsspecifik datamängd för att förstärka önskade beteenden.
Det används betydligt mer sällan än RAG i affärssammanhang och lämpar sig inte särskilt väl för att bädda in specifik kunskap i en LLM, eftersom du inte har kontroll över vilken kunskap modellen väljer att använda i sina svar.
Däremot är det effektivt när man vill att modellen ska svara på ett pålitligt sätt i ett visst format eller med en specifik ton – till exempel för att återskapa ett företags skrivstil genom att finjustera modellen på tidigare innehåll. Den största fördelen ligger ofta i kostnadsbesparingar i större skala: du kan i många fall finjustera en modell som är 10–1000 gånger billigare, för att lösa en uppgift du först validerat med GPT-4.
En växande community finjusterar open source-modeller för att förbättra deras prestanda inom specifika domäner och uppgifter. Bara några veckor efter lanseringen av Llama 3 hade tusentals varianter redan publicerats på Hugging Face. Vi har ännu inte använt någon av dem i projekt – men vi ser det som en sannolik källa till innovation framöver.
Utvärdering av skräddarsydda generativa AI-lösningar
Utvärdering är en grundläggande del av alla digitala tjänster – men det är särskilt avgörande i utvecklingen av generativ AI, där förändringstakten är hög och etablerade best practices fortfarande saknas.
I våra projekt har det ofta varit utmanande att sätta upp effektiva utvärderingsrutiner. Den största svårigheten är att manuellt bygga ett testdataset som gör det möjligt att utvärdera LLM:ens svar. Det innebär vanligtvis att arbeta nära domänexperter för att definiera en uppsättning önskade svar på typiska prompts, och sedan mäta hur väl modellens output matchar dessa. Till exempel när datan ständigt förändras i en kunskapsbas – behöver testsetet också uppdateras regelbundet. Det kräver tid och fokus.
Men det är alltid värt insatsen. Att försöka förbättra modellen genom att lösa enskilda fel leder snabbt till en situation där varje fix skapar nya problem – och helheten blir svår att kontrollera.
RAGAS och LlamaIndex är två ramverk vi har använt för utvärdering, och mer automatiserade testmetoder börjar nu växa fram.
Att använda AI-agenter och verktyg för att automatisera komplexa uppgifter
AI-agenter är ett snabbt växande paradigm för att effektivt utnyttja LLM:er. I stället för att bara besvara frågor får agenter särskilda instruktioner och verktyg som gör det möjligt för dem att självständigt planera, agera och iterera tills de når målet.
Tänk dig till exempel att du söker efter en specifik datapunkt på nätet. Du kan ge en AI-agent tillgång till ett webbsökningsverktyg och instruera dem att testa olika sökfrågor och granska resultaten tills de hittar rätt information.
Olika uppgiftsanpassade agenter kan också dela sina resultat med varandra och delegera uppgifter mellan sig. Det gör det möjligt att skapa nätverk av specialiserade agenter som samarbetar och itererar tills uppgiften är löst.
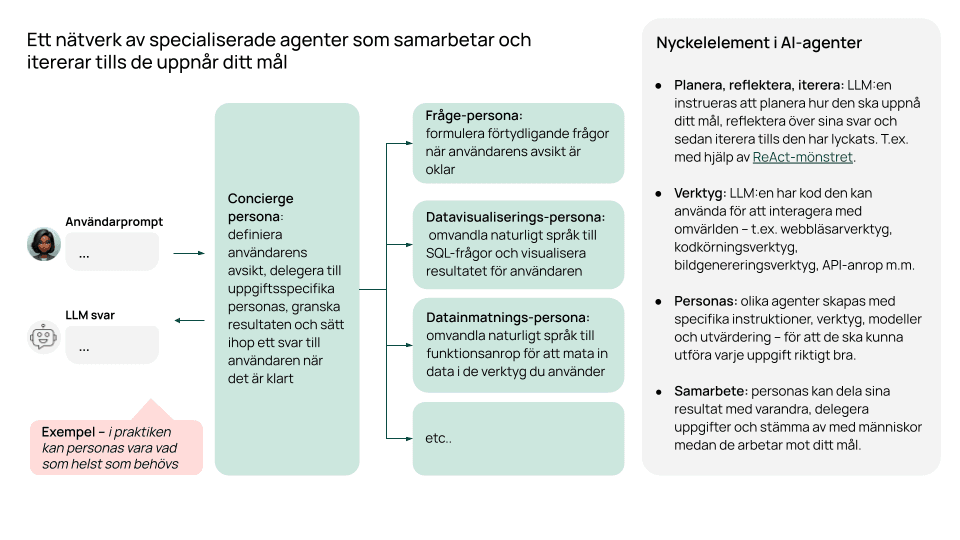
För att fortsätta exemplet: tänk dig att du vill analysera datan som samlats in, och därefter generera en rapport. Din datainsamlingsagent kan då lämna över till en analysagent, som i sin tur skickar vidare till en rapportagent när analysen är klar, helt automatiserat.
Även om området fortfarande är i ett tidigt skede, är det tydligt att agentbaserade metoder kommer att kraftigt utöka vad LLM:er klarar av. I ett test presterade faktiskt GPT-3.5 bättre än GPT-4 när agentbaserade lösningar användes, jämfört med traditionell prompting. Det är bara ett benchmarkresultat – men det bekräftar mycket av det vi själva sett i våra projekt.
Den traditionella maskininlärningens roll tillsammans med generativ AI
Avslutningsvis är det viktigt att komma ihåg att generativ AI bara är ett (väldigt glänsande) tillskott i den bredare data science-verktygslådan. Det utökar vad vi kan göra – och hur snabbt vi kan göra det – men gör på inget sätt traditionella maskininlärningsmetoder överflödiga.
I alla våra produktionsprojekt kombinerar vi LLM:er och traditionell ML, inklusive tekniker som klustring, klassificering och OCR. För vissa uppgifter är ML fortfarande det bättre, snabbare, mer skalbara och mer kostnadseffektiva valet.
Bortom tekniken: ett fullstack-angreppssätt för skräddarsydda AI-lösningar
Tekniken är förstås bara en del av att bygga framgångsrika, skräddarsydda lösningar. För att AI verkligen ska skapa effekt behöver vi identifiera ett problem som är värt att lösa, där AI också är rätt verktyg för uppgiften. Därefter krävs det nästan alltid förändringar i arbetssätt, processer, roller och tankesätt – ibland till och med i verksamhets- eller affärsmodell. Det är det vi kallar ett fullstack-angreppssätt.
Du kan läsa mer om detta i vårt arbetsdokument om generativ AI.
 Jack RichardsonHead of Data & AI Transformation
Jack RichardsonHead of Data & AI Transformation





