Part 2 — Architecting for reality: Engineering the Enterprise Agentic Stack
Most enterprise AI failures don’t look like spectacular blowups. They look like silence: pilots that never become products. The demo worked. Users were excited. Then, Security asked about audit trails. IT asked about identity. Legal asked about data residency. Ops asked about incident response. Finance asked why costs spiked. And the project stalled.
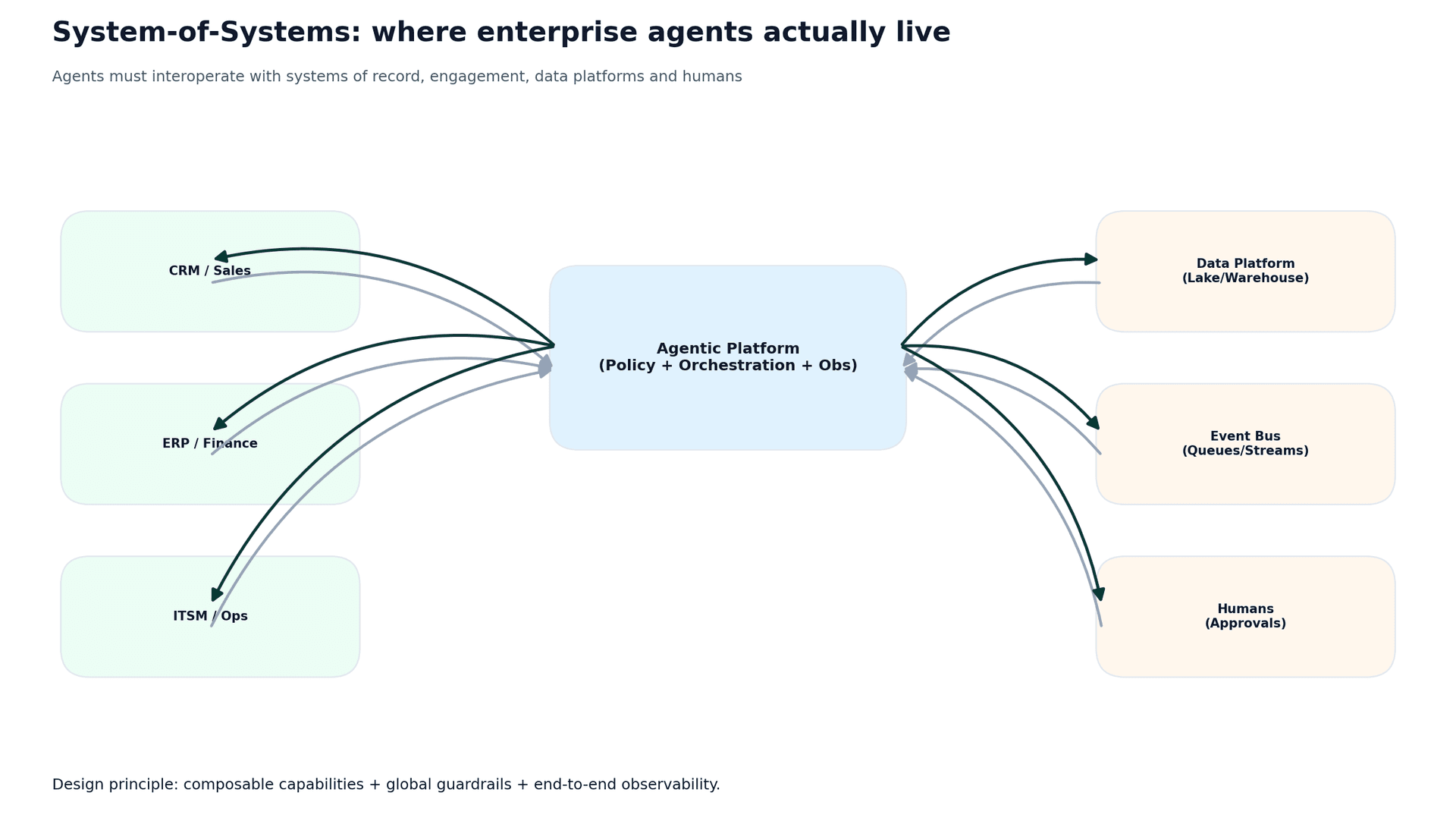
The root causes are predictable—and architectural. Enterprises are systems-of-systems. Agents must interoperate with systems of record and engagement, data platforms, and humans. To scale, you must treat agents like governed services, not clever prompts.
Executive summary
- The top blockers to scaling agent pilots are integration, data quality, and governance, not model capability.
- Enterprise agents operate inside a system-of-systems, requiring global guardrails and end-to-end observability.
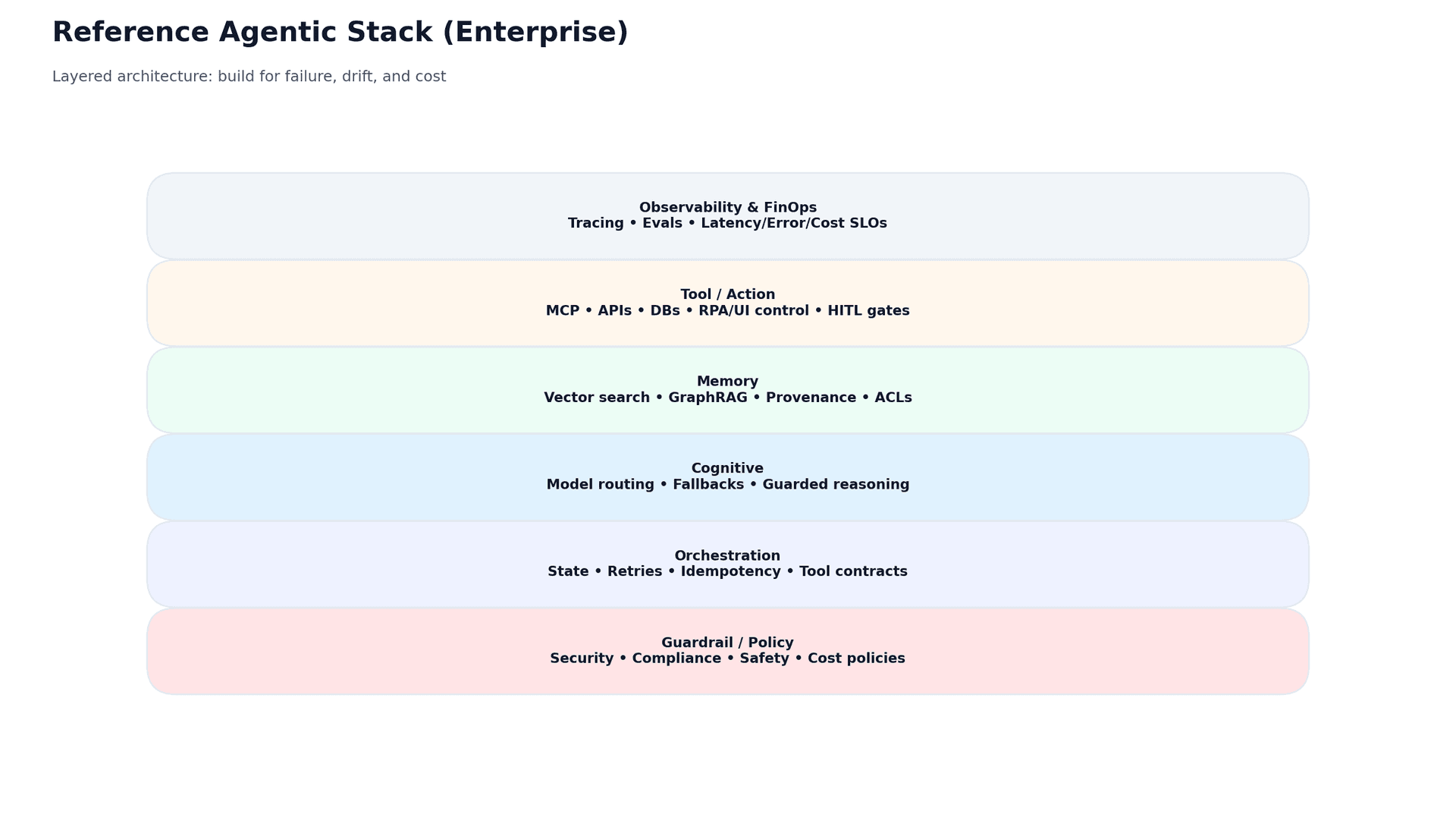
- A practical target architecture separates policy, orchestration, routing, memory, tools/actions, and observability/FinOps.
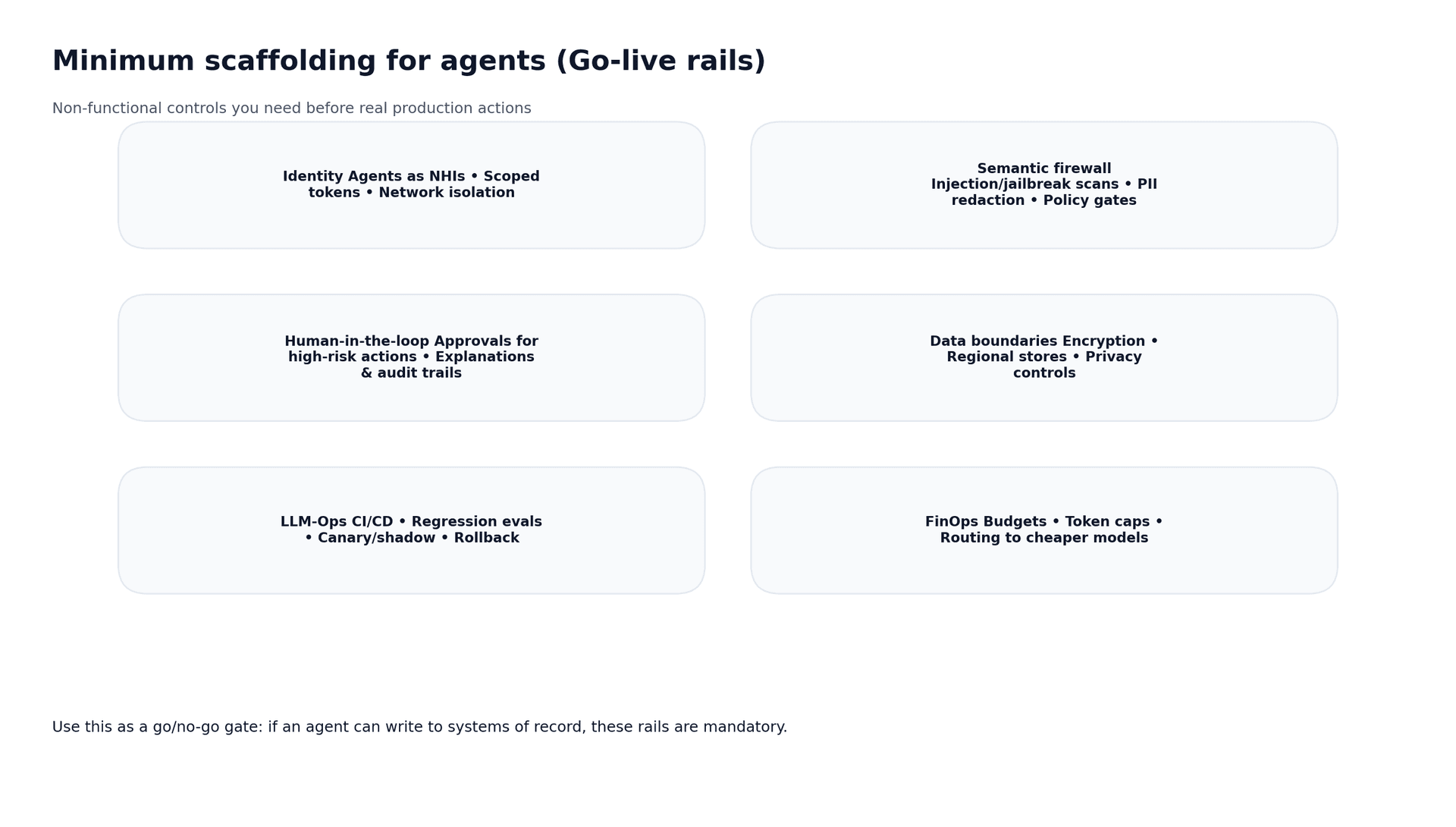
- Minimum scaffolding (identity, semantic firewall, HITL, LLMOps, FinOps) is the go-live gate for action agents.
1) Non-functionals are now the moat
In early pilots, teams optimize for a good demo. In production, enterprises optimize for reliability, security, and predictable economics. Futurice’s market framing is blunt: non-functionals now drive architecture decisions more than model benchmarks.
2) Agents live inside a system-of-systems
An enterprise agent is rarely the whole workflow. It’s a task embedded inside deterministic systems: CRM cases, ITSM incidents, invoice exceptions, RFP workflows. That means agents must integrate with systems of record and engagement, data platforms, and humans, as well as every integration point introduces risk and operational requirements.
3) Failure modes you must engineer for
Most “agent failures” are systems failures. Use this list as a design checklist:
- Prompt injection → tool misuse → unauthorized data access or actions (semantic firewall + allowlists).
- Over-privileged tokens/connectors (NHIs + least privilege + approvals).
- Tool timeouts/partial failures (orchestration retries + circuit breakers).
- Non-idempotent actions (duplicate writes) (idempotency keys + safe retry).
- Prompt/model regressions (eval harness + release gates).
- Runaway token costs (routing + budgets + caps + cost observability).
If you can’t explain how your system behaves under failure, drift, and adversarial inputs, you don’t have an enterprise agent. You have a prototype.
4) Reference target architecture: the Enterprise Agentic Stack
Production programs converge on a layered architecture. Futurice’s recommended reference stack is a pragmatic version of what teams build after real incidents and cost surprises: separate policy from orchestration, routing from memory, tools from observability.
Evidence in Action: Futurice AI Reference Cases
When AI is engineered as a governed workflow inside real systems and integrated with existing tools, the impact is fast in cycle time, cost, and reliability. See a few selected cases below:
- Terveystalo (Nero): Consolidated information from multiple sources into one interface, shrinking information retrieval for customer service (2.5 million calls/year) from ~1 minute to 20–40 seconds—an orchestration win over a standalone chatbot.
- Viestimedia (Renki): Embedded AI into journalists’ daily workflow, driving a reported 20% improvement in operational efficiency with ⅔ of journalists using it daily, highlighting adoption as an integration problem.
- Nordic Telecom: A 6-week AI opportunity assessment with rapid prototyping moved the client from vague intent to a concrete action plan by testing feasibility and value before committing to production build-out.
The pattern is consistent: orchestration + integrated data + human-centric UX + operational rails beats “just picking a better model.”
Harness engineering: when the rails become the product
A useful term for what’s changed in 2026 is harness engineering: everything around the model that makes an agent safe and dependable in production—context management, tool orchestration, sandboxed execution, persistent session state, scoped permissions, error recovery, and observability. It’s the agent’s control plane: analogous to what containers needed from orchestration, networking, policy, and runtime isolation to be operable at scale. 1
This matters because the market is rapidly productizing these “enterprise rails.” Anthropic’s Claude Managed Agents positions the harness as a managed runtime; OpenAI’s updated Agents SDK ships a model-native harness plus native sandbox execution; and cloud platforms now offer agent runtimes with sessions, memory, execution, and metered operational primitives (Google Vertex AI Agent Engine, Microsoft Foundry Agent Service, and AWS Bedrock AgentCore). 1,2,3,4,5
The implication isn’t “pick a vendor and you’re done.” It’s that the differentiator shifts up the stack: the quality of your policies, connectors, evaluation gates, audit evidence, and cost controls—and how well they map to your workflow and risk tier. Treat the harness as a capability layer you can buy, but keep portability in the contracts (tool interfaces, policy gates, eval harnesses) so you can evolve without lock‑in. 1,2
5) Minimum scaffolding for go-live (your gate)
The fastest way to kill trust is to ship an action agent without rails. The fastest way to keep momentum is to adopt a clear go/no-go gate. Futurice’s guidance is to treat agents like services: versioned, tested, budgeted, and governed. 2 In practice, that means putting enterprise rails in place—the shared, reusable production guardrails that make agents safe and operable in a real company: identity/NHIs and least privilege, policy enforcement and safety scanning (e.g. prompt-injection/PII controls), end-to-end observability (traces/logs/metrics), and cost controls (budgets, routing, caps) so behaviour stays predictable as usage scales
A simple go-live rule by risk tier
Use this as an executive-friendly gate before any production launch:
- Low risk (assist-only): allowed-data policy + basic logging + citations; no system writes.
- Medium risk (sensitive read or gated writes): NHIs + least privilege + semantic firewall + HITL approvals + tracing.
- High risk (autonomous actions or cross-domain/event-driven): landing zone + eval-gated CI/CD + SLO/incident ops + FinOps + audit-grade logging.
6) Use standards as scaffolding (not bureaucracy)
When projects stall, it’s often because stakeholders lack shared language and shared evidence. Standards help you establish both without requiring a multi-year governance program:
- NIST AI RMF for risk vocabulary and lifecycle framing (Govern/Map/Measure/Manage).
- OWASP Top 10 for LLM Apps to translate threats into concrete engineering controls (prompt injection, insecure output handling, tool misuse).
- ISO/IEC 42001 to structure an AI management system (policies, objectives, continuous improvement).
- EU AI Act context for risk-based obligations—especially for regulated deployments in Europe.
What to do next
A target architecture and minimum rails create the conditions for scale, but they don’t automatically produce value.
In the final installment of this series, we will introduce the Futurice AI Maturity Model (FAMM) to help you map your company's context to a pragmatic execution roadmap
References
- The New Stack — “AI Agent Harness Pricing Split” (Apr 2026): thenewstack.io/ai-agent-harness-pricing-split/
- Anthropic Claude Platform release notes — Claude Managed Agents public beta (Apr 8, 2026): platform.claude.com/docs/en/release-notes/overview
- Anthropic Engineering — “Scaling Managed Agents” (Managed Agents / harness design): anthropic.com/engineering/managed-agents
- OpenAI — “The next evolution of the Agents SDK” (model-native harness + native sandbox execution) (Apr 2026): openai.com/index/the-next-evolution-of-the-agents-sdk/
- Google Cloud — Vertex AI Agent Engine overview + pricing (sessions/memory/code execution): docs.cloud.google.com/agent-builder/agent-engine/overview ; cloud.google.com/vertex-ai/pricing
- Microsoft — Foundry Agent Service pricing / hosted agents & Code Interpreter sessions (Apr 2026): azure.microsoft.com/pricing/details/foundry-agent-service/ ; learn.microsoft.com/azure/foundry/agents/
- AWS — Amazon Bedrock AgentCore (agent runtime primitives and secure operation): docs.aws.amazon.com/bedrock-agentcore/ ; aws.amazon.com/bedrock/agentcore/
 Adamu HarunaTech Principal
Adamu HarunaTech Principal


